

The challenges in building OCR models
Challenges and innovations in the IT world on Advanced Technology Days 17
Advanced Technology Days was held in Zagreb for the 17th time! The conference has become a traditional gathering of IT enthusiasts in the SEE region with an emphasis on new technologies and innovations in the field.
This year Unitfly had two presenters: our COO Alan Debijađi talked about Azure Synapse Analytics, an Azure platform that combines enterprise data warehouse and big data analytics to ensure centralized management of data lakes and warehouses. On the other side of the coference room, our Software Engineer Dino Grgic presented the challenges of optical character recognition (OCR) models, the topic we will cover today.

Introduction
The process of converting an image of text, or a hand-written text into a machine-readable text, also known as ‘optical character recognition’, became publicly widespread in the early 1990s.
Since then, the technology has undergone a lot of improvements. Nowadays, we are able to digitalize hand-written documents, along with other benefits of OCR.
Are today’s OCR solutions accurate enough and no longer challenging? Do they still require deep learning?
These are some of the questions our colleague Dino wanted to give an answer to in his presentation on this year’s Advanced Technology Days conference.
What is OCR?
Before we get to the bottom of the issue regarding OCR, let’s get to know a term called Computer Vision – a field of artificial intelligence (AI) that enables computers and systems to identify and understand objects in digital images, videos and other visual inputs – and take actions based on that information.
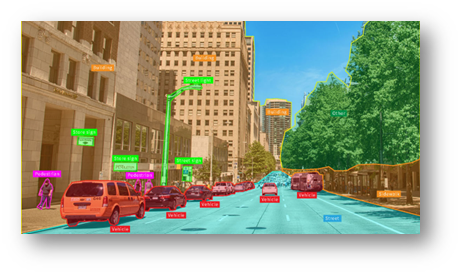
OCR is a subfield of Computer Vision. It recognizes text in an image and converts it in a machine-readable text data. Some of the fields where OCR is used and useful are:
- License plate recognition
- Traffic sign recognition
- Helping the blind and visually impaired reading the text
- Converting handwritten notes to machine-readable text
- Translation from one language to another
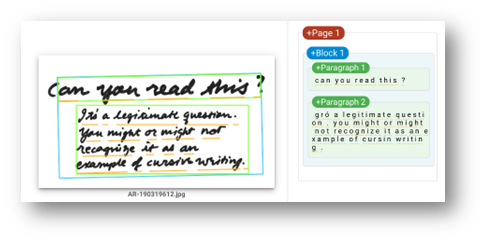

OCR yields very good results for general use cases, however, there are a lot of specific cases where deep learning is still required.
For example, detection of data in unstructured incoming invoices in the Croatian language (and the language your current OCR model works on is English, and doesn’t recognize some specific letters used in Croatian – Č, Ć, Š, Ž… ). This is a perfect example of a field where OCR needs improvement to become a reliable model for solving a requirement.
How to create OCR model
We might need to develop and train our own model if the use case is too specific. In order to do that, we need a set of data – for different fonts, and formats we need to train our computer for better recognition of any given incoming invoice and data in it. More data leads to a better model.
An important note to point out is that this model could be used in this field only (Croatian incoming invoices), but cannot be used, for example, in Arabic incoming invoices – because of the difference in a set of data that was put in it.
3 step process of creating an OCR model
- Pre-processing
Inserting an image in the model, from which we want a computer to learn. Every image goes through a lot of filters before any text is detected. - Text detection + text recognition
Using bounding boxes, we detect the location of the text, and with text recognition, we train the computer to read it. - Post-processing
Converting data that we processed in previous step and generating the output in the form we want – document file, excel sheet, etc.
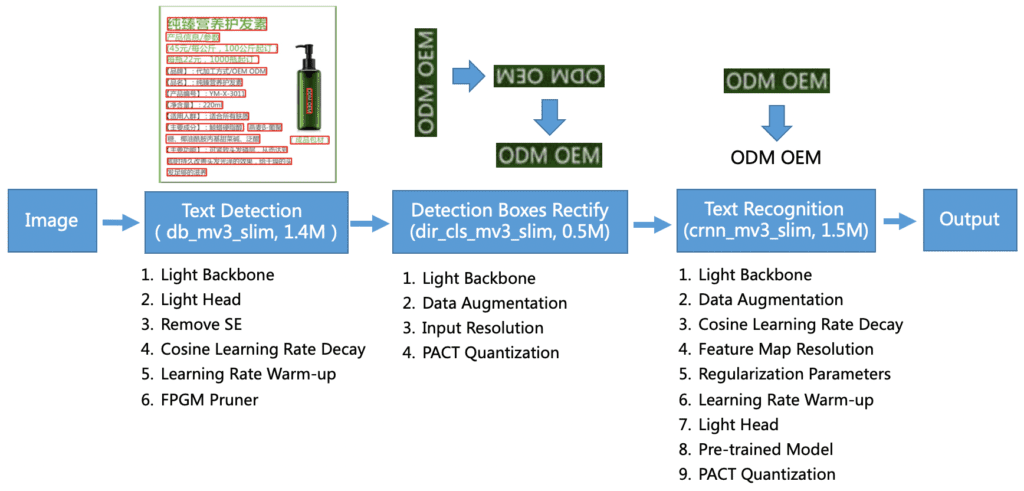
It is easy to recognize regular text, but the ongoing research focuses on recognizing irregular texts – blurred, with the object hiding a part of the text, text on a transparent background with the noise behind it, italic text, bad lightning, etc. …

Source: Chenxia Li, et. al, Picture 5: Technical challenges of OCR algorithms
Source: Chenxia Li, et. al, “Dive into OCR”
Conclusion
There is no such thing as a 100% effective and accurate OCR model. Each OCR model is used for the specific task in mind only. Because of that, it is not possible to generalize the solution easily. Systems depending on OCR depend on its quality, so the OCR field will always seek for improvement in mode accuracy.
The presentation, demo and useful links regarding OCR you can find on Dino’s GitHub repository.

