

Introduction to Azure Data Factory
Every successful company bases its decision-making process on data. In order to make use of all the data flowing around us, we need to understand its core meaning, gather, and analyze it. To ensure you have the data transferred, organized and the whole process scheduled and monitored, the best solution is Azure Data Factory.
Azure Data Factory (ADF) is, by definition, an integration tool in a cloud. To be more specific, ADF is a data movement and data transformation tool. In addition, you can use it as a hybrid data integration tool – connecting to on-premises sources and sources in a cloud.
With the new approach version 2 (v2), Azure Data Factory can be very useful for data movement and data integration.
In fact, we can dare to say that Data Factory is a substitute for a failed implementation of Microsoft BizTalk Services with Azure. Maybe it’s a logical answer to Microsoft BizTalk Server.
Pay-per-use service
BizTalk is an enterprise integration tool with many functionalities and powerful features that come with a high price, while Data Factory is a more affordable pay-per-use service. Pay-per-use model allows the customer to have a lean and agile approach, starting small then scaling up. Every activity can be controlled and monitored, how many resources were used and how much will be charged eventually. Data movement, for example, from SQL database to a Web Service would cost 0.125$ – 0.25$ per hour.
ADF is, by design, more Extract-and-Load (EL) and Transform-and-Load (TL) then traditional Extract-Transform-and-Load (ETL). Since you can use ADF in various ways, we see an opportunity to explore the potential of it.
In the same way as any other integration tool, ADF connects to the source, collects the data, usually does something clever with it, and sends the processed data to a destination. The final touch is monitoring all the processes and transfers.
Let’s review these steps:
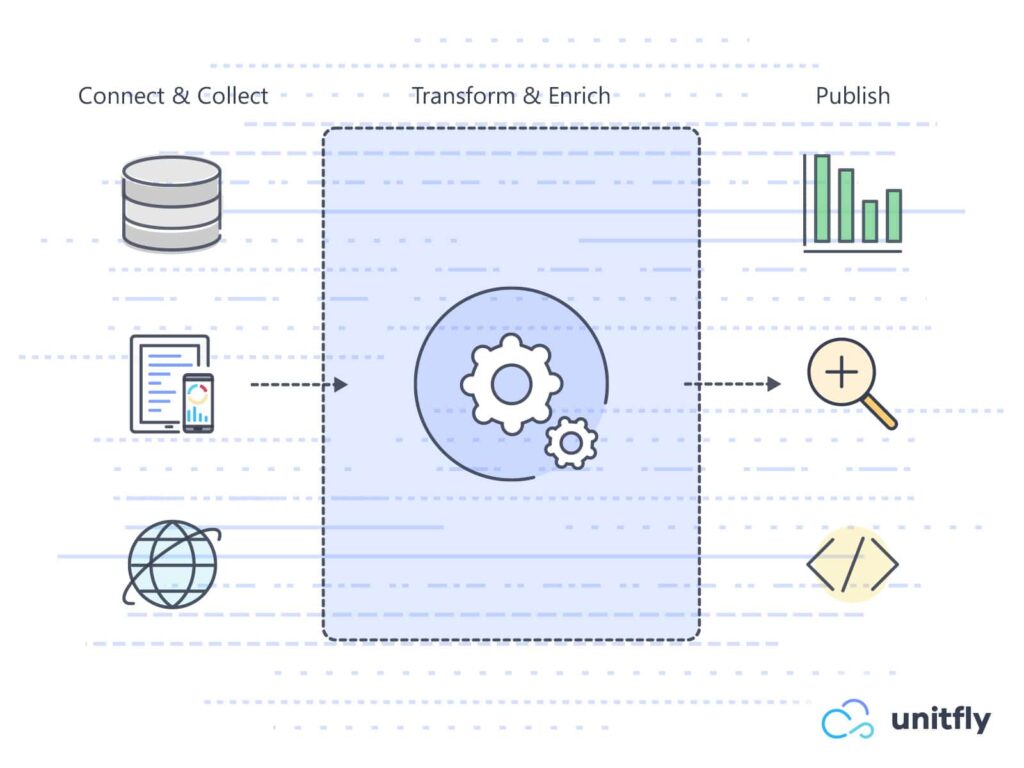
- Connect and collect – connecting to various types of data sources, on-premises, in the cloud, structured, unstructured, in different time intervals, etc. ADF has built-in connectors, but you can also develop your own.
- Transform and enrich – processing and preparing data for destination. Data can be transformed using computed services in Azure like HDInsight Hadoop, Spark, Data Lake Analytics, Machine Learning, as well as a custom service.
- Publish – transferring processed and business-ready data in a consumable form into a database, service, or some analytics engine. From that point on you can use the data to bring a business value to a business user using any business intelligence tool.
- Monitor – monitoring scheduled activities and processes. Support is crucial in integration processes, as you always want to know did the magic happen or not.
Architecture
Pipeline & Activity
Pipeline is a logical grouping of activities that perform a task together. Within a logical grouping all tasks can be logically separated and individual. Pipelines can be scheduled and executed via triggers or run manually, on demand. Pipeline is an orchestration or a workflow and activities as shapes in BizTalk orchestration. They consist of four types:
With custom activities you can perform data movement or data transformation activity. In fact, you can do anything you want. In custom activity, the only limit is your imagination.
Dataset
Dataset is similar to a scheme in BizTalk, except dataset can have an information about a path to a specific resource. It represents a structure, a named view that points or references data you want to use in your activities as inputs or outputs. Datasets are, for example, files, folders, tables, and documents.
Linked service
Next, linked service is used as a link between a data store and a data factory, like a connection. Linked service can have compute resources for:
- HDInsight
- Azure SQL Database
- Azure Blob Storage
- Machine Learning
New capabilities in ADF version 2
In Azure Data factory version2, main capabilities were summarized:
- Control flow and scale
- Deploy and run SQL Server Integration Services (SSIS) packages in Azure
Control Flow and Scale
In order to make activities and pipeline more flexible and reusable, here are some updated capabilities that you can do in pipeline:
Control flow
- Chaining activities in a sequence within a pipeline
- Branching activities within a pipeline
- Parameters
- Parameters can be defined at the pipeline level and arguments can be passed while you’re invoking the pipeline on-demand or from a trigger.
- Activities can consume the arguments that are passed to the pipeline.
Custom state passing
- Activity outputs including state can be consumed by a subsequent activity in the pipeline.
Looping containers
- For-each
- Until
Trigger-based flows
- Pipelines can be triggered by on-demand or wall-clock time.
Delta flows
- Use parameters and define your high-watermark for delta copy, while moving dimension or reference tables from a relational store either on-premises or in the cloud to load the data into the lake.
Deploy SSIS packages to Azure
Data Factory can provision Azure-SSIS Integration Runtime, so now, SSIS workloads can be executed on Azure Data Factory.
Summary
All in all, Microsoft is putting an extra amount of effort to improve functionalities and the usage of integration tools in the cloud. Azure Data Factory is a great example of how a market analysis, together with a customer survey, led to a great product/service. With ADF v2, there is even more flexibility and usage for a potential customer, allowing an agile and lean approach for a low price. We can also have a proof of concept ready for you in a jiffy and you won’t have to spend a lot.
We appreciate the direction and strategy of ADF. Whether you need a simple data movement and synchronization or a complex orchestration, it is a product with a lot of perspective. True, you’ll have to spend a little more time on the code, but its engine has a lot of potential. That’s a big strength of Azure Data Factory, we have recognized that and made it a part of our implementations. Contact us and describe your case, maybe we can help!


